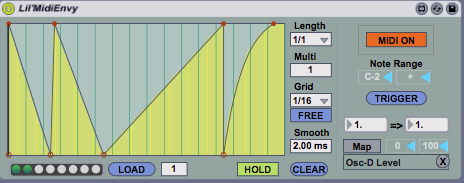
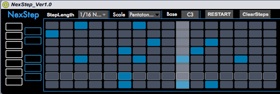
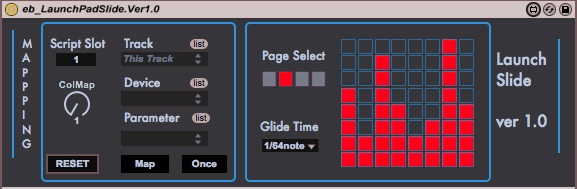
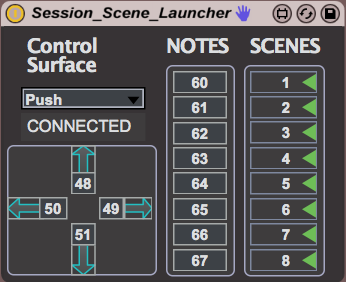
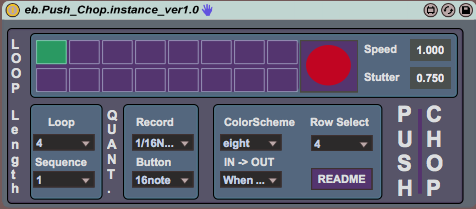
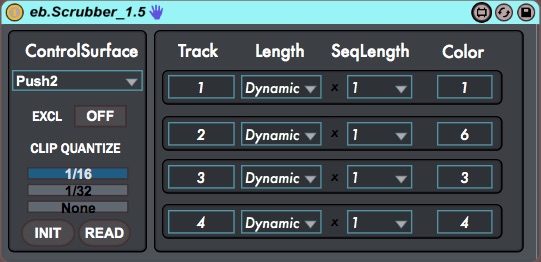
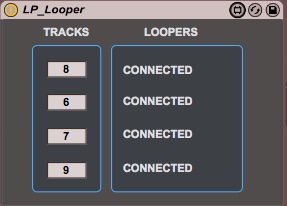
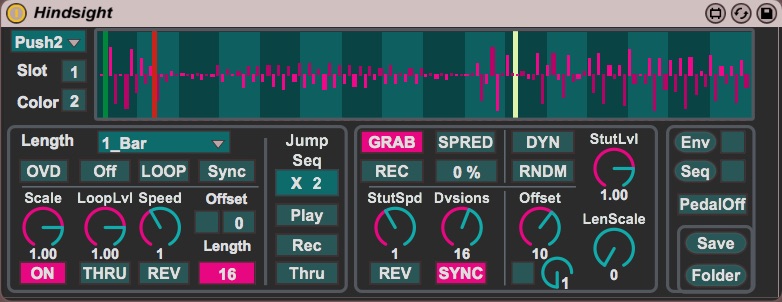
Hindsight is a looping engine built in Max 7 for Ableton Liv...
This website uses cookies.
Clicking “Accept” means you consent to your data being processed and you’ll let us use cookies and other technologies to process your personal information to personalize and enhance your experience.
Click “Close” to deny consent and continue with technically required cookies that are essential for the website to function.